
Машинное обучение в медицине: ищем опухоль при помощи логистической регрессии

У всякого безумия есть своя логика
Уильям Шекспир
Машинное обучение — это подраздел искусственного интеллекта (ИИ) и наук о данных, базирующийся на использовании данных и алгоритмов для имитации процесса наработки опыта человеком с постепенным повышением точности.
С помощью статистических методов алгоритмы обучаются классифицировать данные, строить прогнозы и улучшать процессы сбора и анализа данных. Результаты работы моделей могут влиять на дальнейшее принятие решений, в идеале приводя к оптимальному выбору.
В медицине мы постоянно сталкиваемся с обилием данных: достаточно вспомнить, как выглядит история болезни пациента, особенно не с одной госпитализацией. Также постановка диагноза требует анализа всей имеющейся информации по пациенту, что крайне трудозатратно. Попытки внедрить автоматизацию принятия решений медицинскими специалистами уже происходят, например, в визуализирующих методах диагностики, в обработке гистологических изображений.
Попробуем решить одну из диагностических задач методами искусственного интеллекта.
Собственно набор данных (датасет, dataset), над которым мы будем проводить машинлернинговские операции, размещен в открытом доступе на популярной платформе для соревнований по анализу данных Kaggle.
Это сведения о пациентах со злокачественными и доброкачественными опухолями молочной железы.
Задача: предсказать, какой диагноз имеет пациент. Это задача классификации — отнесения объекта к какой-либо категории.
Для начала разберем, как представить диагноз в виде переменной. Это точно не количественная величина, тогда что?
Как мы уже решили, диагноз — это в какой-то степени категория, к которой мы относим случай. При этом значение точно, без промежуточных вариантов. Можно сравнить с днями недели. Если есть точки на графике, обозначающие события определенного дня, то ни одна из точек не может быть между понедельником и вторником. Если что-то произошло в понедельник, то оно произошло в понедельник, — все просто. В нашем случае опухоль или доброкачественная, или злокачественная.
В качестве инструмента для работы с категориальными переменными мы будем использовать логистическую регрессию. Эта модель выдает вероятность соответствия той или иной категории.
Немного о самой модели. Логистическая регрессия — один из статистических методов классификации с использованием линейного дискриминанта Фишера. Она входит в топ часто используемых алгоритмов при исследовании данных.
Значением функции является вероятность того, что данное исходное значение принадлежит к определенному классу. Представим, что у нас есть какое-то пространство, в котором в виде точек размещены наши исходные значения. Мы можем поделить это пространство с помощью линейной плоскости на подпространства, в которых будут близкие значения, наиболее вероятно принадлежащие одному классу (типу, категории). Уже упомянутый линейный дискриминант Фишера определяет направления, проекции на которые лучше всего разделят классы. В итоге получаются разделяющие линейные плоскости.

Для реализации наших целей будем использовать Google Colab или Jupyter Notebook (не будем погружаться в аспекты его установки, просто воспользуемся версией в браузере, далее выбираем Try Classic Notebook).
Я опишу работу в Google Colab. Блоки кода добавляются с помощью «+Код», запускается код с помощью кнопки со стрелкой слева.
Сначала призовем все необходимые инструменты — готовый код в виде библиотек с уже реализованными за нас функциями, которые мы будем использовать
Загружаем данные по пациентам (скачанные с Kaggle) для работы в ноутбуке. Для этого в поле слева выбираем «Файлы», затем «Загрузить в сессионное хранилище». Последнее означает, что, к сожалению, данные будут храниться лишь во время текущей сессии, то есть после закрытия коллабного ноутбука они исчезнут, как Золушка с бала, и их вновь придется загружать.
С помощью команды .head выведем несколько начальных строк нашей таблички (формат .csv, в котором представлены данные по пациентам, это такой табличный подвид)

Вывод программы («голова» таблички)

Посмотрим, что у нас за данные
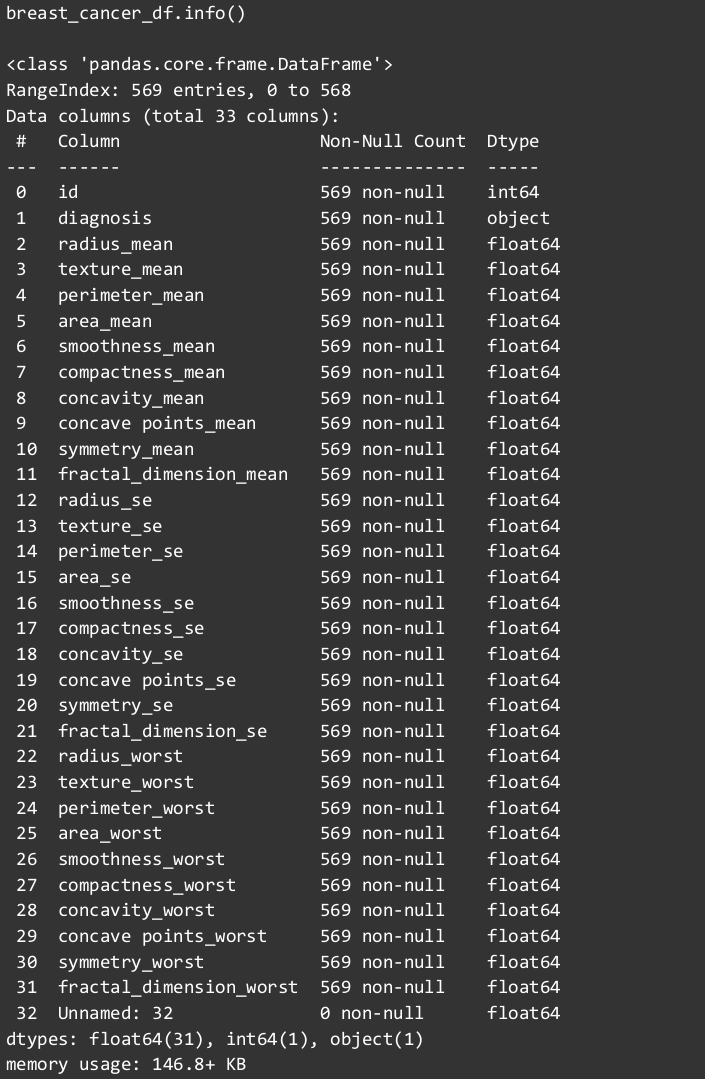
Итак, выяснили, какие есть столбцы, сколько в каждом столбце ненулевых значений, а также какого типа данные в каждом из столбцов. Проверим, есть ли пропуски в значениях.

Нам повезло: нулевых значений ноль. Значит, не нужно как-то заполнять либо наоборот, удалять такие случаи и уменьшать количество пациентов в выборке.
Нам не нужны столбцы «id» и «Unnamed: 32», поскольку они не играют никакой роли в прогнозировании. Удаляем их

Далее нам нужно закодировать значения столбца «диагноз» (который сейчас представлен в виде букв «М» [malignant, злокачественный] и «В» [benign, доброкачественный]) в их числовые представления.

Обозначим входные и выходные данные:

Нашу модель надо сначала обучить, а потом проверить, как она справилась с этой задачей (протестировать). Для этого разобьем данные на тестовые и тренировочные. В качестве инструмента будем использовать модуль train_test_split библиотеки scikit-learn.

Затем необходимо стандартизировать данные. Для «скармливания» модели необходимо, чтобы распределение имело среднее значение 0 и стандартное отклонение 1. Это сделает StandardScaler.

Наконец, призываем непосредственно нашу логистическую регрессию, все из той же библиотеки scikit-learn.
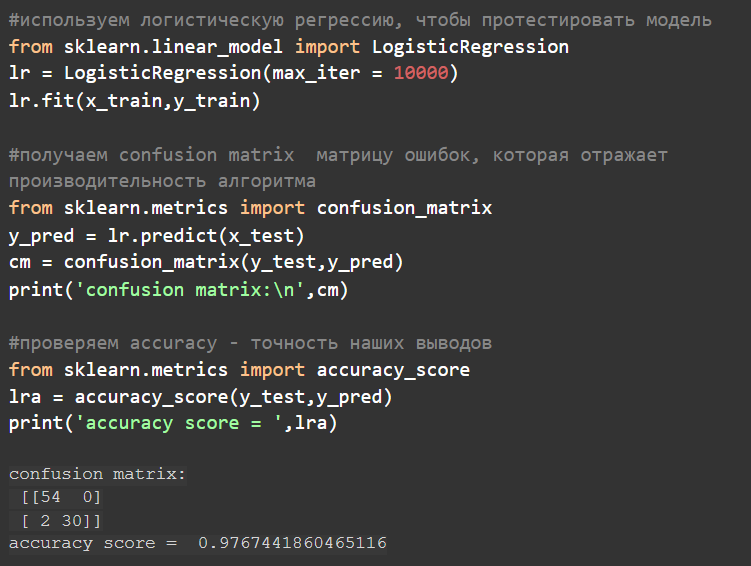
Проверим эффективность нашей логистической регрессии.
Начнем с confusion matrix (матрица ошибок). Матрица представлена в выводе программы в прямоугольных скобках: общие для всей матрицы и внутри отдельные для каждой строки.

Здесь ŷ — это ответ алгоритма на объекте (то, что предсказала модель), y — истинная метка класса на этом объекте (то, как это было указано в нашем изначальном датасете).
Accuracy — это доля правильных ответов алгоритма, получилось (с округлением) 0,977 или 97,7 %.
Формула для расчета accuracy:
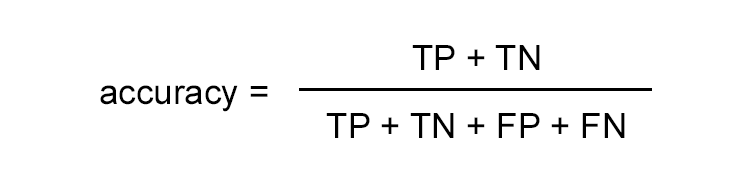
где TP — True Positive; TN — True Negative; FP — False Positive; FN — False Negative.
Итак, модель справилась неплохо. Можно ли еще лучше, проверим на других моделях в новых статьях.
Ссылки на ноутбук:
